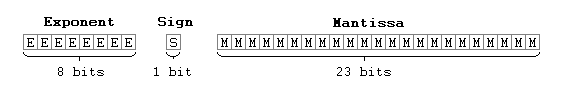
The 'math package' is a reasonably discrete block of code that provides floating-point arithmetic capability for the rest of BASIC. It also includes some math functions, such as SQR (square root) and is probably the hardest part of BASIC to understand. There are three general reasons for this :
Consider an everyday decimal number such as 317.25. The digits that make up this and every other decimal number represent multiples of powers of ten, all added together:
|
So writing 317.25 is basically just shorthand for 3*102 + 1*101 + 7*100 + 2*10-1 + 5*10-2. The shorthand form is far more readable, and that's why everybody uses it. At risk of labouring the point, the below table should clarify this.
|
||||||||||||||||||||||||||||||||||||||||||
Now consider the same number in binary (base two). The decimal number 317.25, expressed in binary, is :
|
And here's a table like the decimal one above, which should make it completely clear (remember 'bit' is short for 'binary digit') :
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Now let's think about decimal numbers again. Another way of representing the number 317.25 is like this : 3.1725 * 102. Yes we've split one number into two numbers - we've extracted the number's magnitude and written it seperately. Why is this useful? Well, consider a very small number such as 0.00000000000588. Looking at it now, precisely how small is that? That's a lot of zeros to work through. Also, let's pretend we're using very small numbers like this one in a pen+paper calculation - something like 0.00000000000588 + 0.000000000000291. You'd better be sure you don't miss out a zero when you're working the problem through, or your answer will be off by a factor of 10. It's much easier to have those numbers represented as 5.88 * 10-12 and 2.91* 10-13 (yes the second number had an extra zero - did you spot that?). The same principle applies for very large numbers like 100000000 - it's just easier and less human error prone to keep the magnitudes seperated out when working with such numbers.
It's the smallest of small steps to get from this form of number notation to proper scientific notation. The only difference is how the magnitude is written - in scientific notation we lose the magnitude's base and only write it's exponent part, thusly : 3.1725 E 2. The part that's left of the E, the 3.1725, is called the mantissa. The bit to the right of the E is the exponent.
Let's go back to considering 317.25 in binary : 100111101.01. Using scientific notation, this is 1.0011110101 E 1000. Remember that both mantissa and exponent are written in binary that exponent value 1000 is a binary number, 8 in decimal.
Consider the eternal problem of having a finite amount of computer memory. Not having infinate RAM means we cannot represent an infinite range of numbers. If we have eight bits of memory, we can represent the integers from 0 to 255 only. If we have sixteen, we can raise our range from 0 to 65535, and so on. The more bits we can play with, the larger the range of numbers we can represent. With fractional numbers there is a second problem : precision. Many fractions recur : eg one third in decimal is 0.33333 recurring. Likewise, one tenth is 0.1 in decimal but 0.0001100110011 last four bits recurring in binary.
So any method we choose for storing fractional numbers has to take these two problems into consideration. Bearing this in mind, consider the two possible approaches for storing fractional numbers :
Why is floating point better than fixed point? Let's say we have 32 bits to play with. Let's use fixed point and assign 16 bits for the integer part and 16 for the fractional part. This allows a range of 0 to 65535.9999 or so, which isn't very good value, range-wise, for 32 bits. OK, lets increase the range - we'll change to using 20 bits for the integer and 12 for the fraction. This gives us a range of 0 to 1,048,575.999ish . Still not a huge range, and since we've only got 12 bits for the fraction we're losing precision - numbers stored this way will be rounded to the nearest 1/4096th.
Now lets try floating point instead. Lets assign a whopping 24 bits for the mantissa and 8 bits for the exponent. 8 bits doesn't sound like much, but this is an exponent after all - with these 8 bits we get a range of -128 to +127 which is roughly 10-38 to to 1038. That's a nice big range! And we get 24 bits of precision too! It's clearly the better choice.
Floating point is not a perfect solution though... adding a very small number to a very large number is likely to produce an erroneous result. For example, go to the BASIC emulator and try PRINT 10000+.1. You get 10000.1 as expected. Now try PRINT 10000+.01 or PRINT 100000+.1. See?
Normalisation is the process of shifting the mantissa until it is between 0.5 and 1 and adjusting the exponent to compensate. For example, these binary numbers are unnormalised :
After normalisation these same binary numbers become :
blah
There was no industry standard for floating-point number representation back in 1975, so Monte had to roll his own. He decided that 32 bits would allow an adequate range, and defined his floating-point number format like this :
The 8-bit exponent field had a bias of 128. This just meant that the stored exponent was stored as 'exponent+128'.
Also, the mantissa was really 24 bits long, but squeezed into 23 bits. How did he save an extra bit of precision? By considering zero as a special case, indicated by exponent zero. Any non-zero number will always have a mantissa with a leading 1. And since the first bit is always going to be 1, why bother storing it?
The intermediate storage of unpacked fp numbers is undefined and seems to be generally done on the fly.
fixme: put example of normalising and denormalising.